
"The essence of the beautiful is unity in variety."
- Mendelssohn
My gears aflame
I remember being told, many years ago when I started university, that Information Technology is a numerate discipline. I had been admitted onto the IT course on the strength of a high-school biology certification. That was my “technical competency”. The professors assured me, however, that I did not need to be an expert mathematician. The essential requirement, they said, was just to be able to work with numbers.
I took that to mean I needed to be able to add and subtract, which I had mastered at the age of six or seven, or perhaps a couple of years later when I suppose I must have been about twelve. Anyway, it turned out that they really meant I had no obligation to study mathematics beyond second order calculus. You could smell my poor gears burning as I hurtled into Remedial Class City. It can be argued that I have effectively remained there, trying to deduce inflection points on my fingers and toes, ever since.
I am the least numerate person you will ever meet in the IT industry. The people working in the office canteen are more mathematical than I am. At least they can work out the change. For my part though, numbers induce within me an absurd feeling of dread. They are at once both my nemesis and my nightmare. They have left me with my very own case of imposter syndrome. When will my arithmetic incompetence be exposed to all, I chew my nails wondering? When will I finally be caught out?
Ducking and diving, bobbing and weaving
Agile coaching can be a good hiding place for someone like me, at least until metrics are discussed. Fortunately, it's possible to kick the can down the road for a while before that actually happens. An agile coach might assert, with justification, that true value lies in the product increment and not in throughput, velocity, or other proxy measures. Sprint capacity planning, you can also argue, is never meant to be a sufficiently exact science for which a mathematical approach might truly apply. You can rightly claim that estimates are just that – estimates - and that a team merely needs to get its arms around how much work it thinks it can take on. You might also assert that "agile team members should take care not to become story point accountants" - spitting out that last word as I do, like a hard-core numerophobe.
Sometimes though, an agile coach really does have to look at the numbers. If a Product Owner wishes to make evidence-based future delivery projections, for example, then it will be hard to help without conveying an understanding of burn rates, capacity, or throughput. Then there are times when a quantitative approach is arguably less essential, and yet you know in your heart it's the best option. Flow optimization during a Sprint can demand the analysis of cycle times for example, and not just the eye-balling of a team board for bottlenecks. Improving service level expectations can mean that work-item age ought to be assessed, since there are times when a general reflection on team performance just won’t be enough to cut it.
Crunch time
Sprint Planning is another occasion when an irredeemably scattered brain, delinquent in mathematical measure, can be forced into jackboots and expected to crunch numbers. It’s a formal opportunity to use the best data available in order to provide the best possible time-boxed forecast of work. According to the available historical data, how much work can a team reasonably expect to undertake during a Sprint? It’s time for you to challenge any numeracy demons you may have.
If you step up gamely to the mark, you’ll bend your mind around a product backlog’s size and the rate at which a team burns through it. A forecast of Sprint capacity and projected delivery dates will hopefully lurch into view. Pushing the envelope further, you might also factor in the possibility of a Sprint Backlog growing during the iteration. You elicit a burn-up chart to accommodate such eventualities, and then cheekily express disdain for mere burn-downs. Apart from an occasional dalliance with cumulative flow and Little’s Law, that’s about as far as a mathematical derelict such as I will generally dare to venture into the arcane world of numbers.
Fortunately, I have been able to comfort myself for years with the knowledge that, however incompetent I might be in terms of mathematical ability, most of my peers will demonstrate no higher accomplishment. While they must surely be better at grasping metrics than I am, for some reason they always evidence the same dilettante standard of burn-ups and burn-downs. With an ongoing sigh of relief, I have found again and again, that I can wing my way past the whole issue. Nobody seems to care about fancier metrics than those I can actually cope with. The bar has not been set high and even I might hope to clear it.
Raising the bar
The problem is, these usual measures will typically express a precision with limited respect for accuracy. If we have to forecast when a delivery is likely to be made, for example, then we may offer a particular number as our answer. From the Product Backlog burn rate, we might project that the relevant increment will be forthcoming in “Sprint 12”. The calculation we have performed will demonstrate that our assertion is fair. Yet we will also know that the number we offer is uncertain, and that the increment might not be provided in Sprint 12 at all.
We can usually express greater confidence in vaguer terms, such as a range. It might be wiser to say “delivery will probably happen between Sprints 11 and 13”. You see, the more precise forecast of “Sprint 12” is not very accurate. It is a rough number precisely stated. We offer it as cipher for a vaguer and truer answer. This is a game we play with our stakeholders. We know, and expect them to know, that any number we forecast may not be accurate. It is an estimate.
Why don’t we offer the sort of range we can have better confidence in, whenever we have to make a forecast? Why are we obsessed with giving a precise number no matter how unreliable it may be?
Part of the answer lies in our cultural reluctance to be vague, even under conditions of high uncertainty. We assume that someone who fails to be exact cannot be on top of their game. The charlatan who deals in fantasy numbers with precision is respected, while the careful analyst whose stated range actually proves reliable is held to be of lesser accomplishment.
Fortunately, there is a way out of this state of affairs. We can raise the bar and still hope to meet it. All we need to do is to ensure that any “vagueness” we express – such as a range of dates - accurately captures the uncertainty we are dealing with. If we can evidence that velocity is stable to within plus or minus 20% every Sprint for example, then the range we offer in a future prediction ought to reflect that established variation. In truth, the range we give will not be “vague” at all. It will be a range precisely articulated, and it will be as accurate as it is founded on hard data and careful analysis.
An example
Let’s go through a worked example. This is entirely from real-life by the way, and reflects an actual situation where I joined a team as a Scrum Master. All of the data is real and nothing has been made up.
The situation is that the team has been Sprinting for a while with iterations two weeks in length. There is a Product Backlog of an estimated 510 points remaining. We know the team velocities for Sprints 4, 6, 7, 8, 10, 11, and 12. These were 114, 143, 116, 109, 127, 153, and 120 points respectively. We don’t have the data for any other Sprints and some Sprints are evidently missing. It doesn’t really matter though. We just need a representative set of recent velocities from which variation can be evidenced.
We can see that the distribution falls between 109 and 153 points and with no obvious pattern to the scattering. We could of course work out the average burn rate, which is 126 points, and then estimate that it would take just over 4 Sprints to complete the 510 points of work. However, as we have already discussed, when we take an average we are effectively throwing away the variation in order to arrive at our answer, and so we lack an understanding of its accuracy. When we average stuff out, it should be because the variation is annoying and we genuinely want to throw it away. With our greater ambition however, we want to make use of any variation so as to deduce a more useful and reliable range.
The first thing to do is to express the data we have in a more flexible way. Each Sprint lasted 10 working days. If a Sprint completed X story points of work, that means a typical point for that Sprint will have taken 10/X days to clear. We can now produce the following table from the data we have.

If you were asked to build a simulation of how long the 510-point backlog might take to complete, you could use the above data to help you. You’d pick one of the “Typical Days Per Point” values at random 510 times, and then add the set of numbers all up. If you ran the simulation once, it might come to 40.91 days. If you ran that simulation twice more, you could get totals of 40.63 and 41.35 days. On each occasion, you would be running a realistic simulation of how the team might be expected to saw away at 510 story points of work.
If you ran the simulation a hundred times, you’d get even more data to look at. However, the volume of data could then prove a bit overwhelming. So, let’s group the run-times we get from a hundred simulations into 10 buckets, each covering one-tenth of the time between the fastest and slowest. In other words, we’ll count the number of runs which fall within each of the equally-sized time-boundaries of ten buckets.

OK, all of the runs add up to 100. What we appear to have though is a concentration of runs in buckets 4, 5, 6, and 7, with a peak in bucket 6 and a tail-off towards the first and last buckets. In other words, the 510-point backlog is more likely to complete in the 40.8 to 41.09 day-range than at any other point in time. Let’s chart this to better visualize the results.
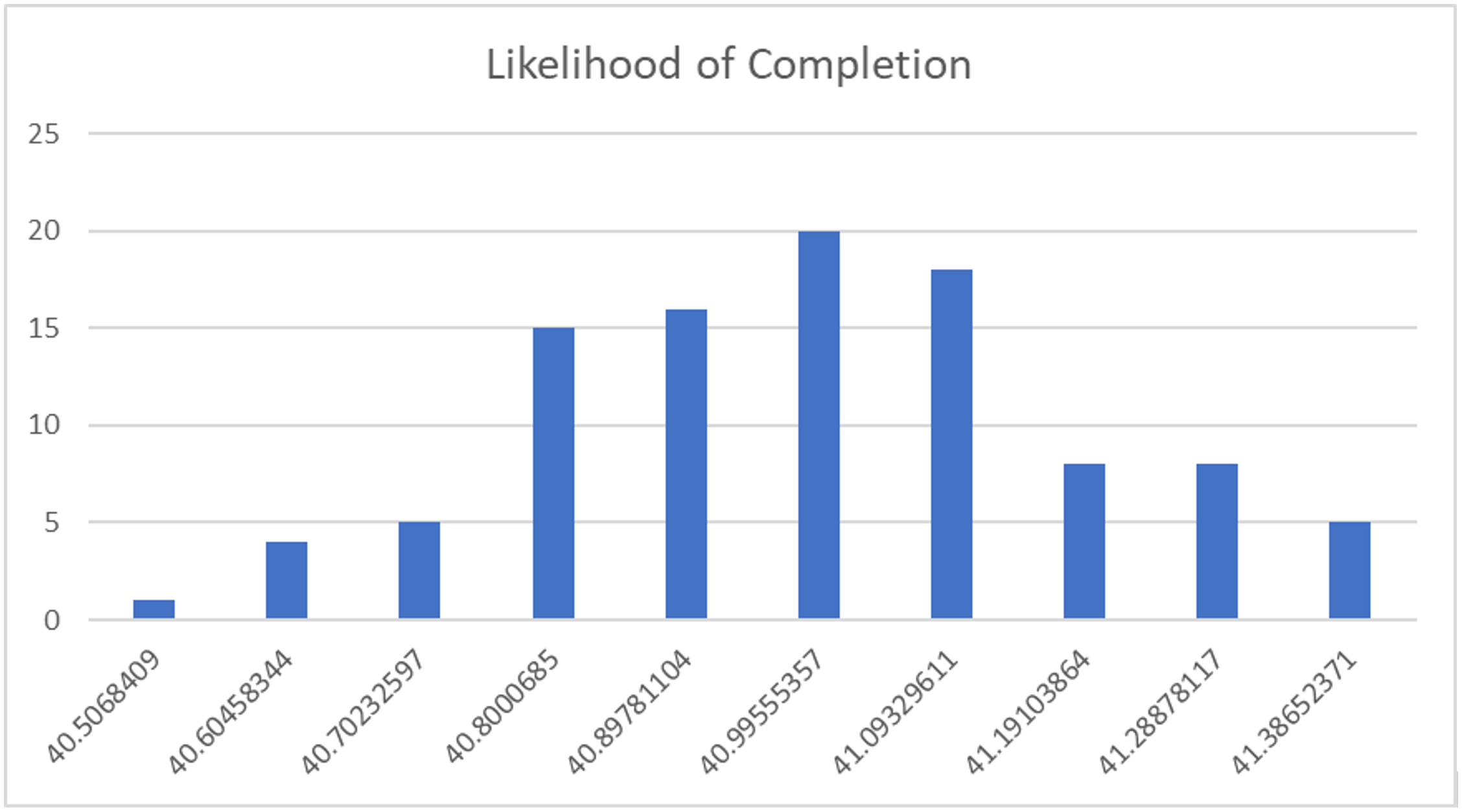
Now let’s run a thousand simulations, and see if this pattern can be confirmed and if it emerges even more clearly.

 By Jiminy, so it does. There really is a clustering. In fact, it’s the sort of thing a biologist might recognize as a normal distribution, or “bell curve”. This type of curve is encountered frequently when studying population distributions, height or biomass variation between individuals, pollutant concentrations, or other events which - when examined in the small - might appear to be without pattern.
By Jiminy, so it does. There really is a clustering. In fact, it’s the sort of thing a biologist might recognize as a normal distribution, or “bell curve”. This type of curve is encountered frequently when studying population distributions, height or biomass variation between individuals, pollutant concentrations, or other events which - when examined in the small - might appear to be without pattern.
This means that if stakeholders wish to know when a given item occupying a certain position on the backlog is likely to be completed, we can do better than to calculate a time based upon a potentially misleading average. Instead, we can show them the time-range in which delivery is likely to happen, and the level of confidence we would have in delivery occurring within it.
Most occurrences cluster around the average - but few if any will actually be the average. Very few people are of exactly average height, for example. Remember that an “average” can be stated precisely but rarely proves to be accurate.
Note also that if we were measuring throughput rather than velocity - or had a rule in which each story must be scoped to one point - then 10/X would effectively represent the “takt time” for that Sprint. This can be a better alternative to story point estimation in so far as it takes a team closer to gauging the actuals of stories completed.
End note
We can never guarantee the certainty of a forecast. The scope of work can grow, items can be re-prioritized, and unforeseen events can always happen. True value will always lie in the increment a team delivers, and not in story points.
Nevertheless, when we collect metrics, such as the velocities attained over a number of sprints, we ought to remember that critically important detail can exist in the variation. All too often we just work out a forecast such as an average burn-rate, and throw the texture of the available data away. Yet in truth, we don’t have to give stakeholders a single “precise” date for delivery in which we can express little confidence. We can do better, and show them the projected range from a thousand or more simulated scenarios.
The process we have covered here is sometimes referred to as a “Monte Carlo” method. This is a class of algorithms which use large-scale random sampling to generate reliable predictions. The technique was implemented computationally by Fermi, Von Neumann, and other physicists at the Los Alamos laboratory in the 1940’s. They were working on problems such as how to work out the likely penetration of neutrons into radiation shielding. It’s generally applicable to complex phenomena where the inputs are uncertain, and yet the probability of outcomes can be determined.
I suppose it’s possible that the world’s great nuclear physicists aren’t much good at working out their change in the canteen either. What they are certainly very good at, however, is recognizing how new information – such as a reliable forecast - can be inferred or deducted from observations which others ignore or take for granted. That’s a very special kind of skill.
As a mathematical blockhead, I can’t lay claim to either of these abilities. What I can do though is to stretch a little. I can raise the bar a touch, and perhaps hope to meet it. You can too. We aren’t restricted to working out an average velocity which we can plug in to burn-rate projections, for example. Monte Carlo analysis is just one illustration of why we should take care before stripping the texture of our data away. We should always seek to provide stakeholders with better information, using the data we have, and by the considered inspection and adaptation of our method.